Overview:
For the initial blog post, we performed EDA and built the baseline model. The accuracy scores are 88.5% for root, 94.4% for vowel and 96.0% for consonant. The major resources we used are Kaushal Shah’s Kaggle notebook for modelling and Gabriel Preda’s Kaggle notebook for EDA. It is worth noting that Kaushal Shah’s model fitting utilizes data augmentation for creating more training data.
EDA
The dataset contains 200,840 training handwritten Bengali grapheme images. Optical character recognition is particularly challenging for Bengali since there are in total 168 classes of grapheme roots, 11 classes of vowel diacritics, and 7 classes of consonant diacritics in Bengali language.
Below are three plots that show the distributions of class values in the dataset. We plotted the most frequent 20 classes/values of grapheme roots, all values of vowels and all consonant diacritics. Grapheme roots and vowel diacritics are distributed in smooth trends, but we can see a big gap in the use of consonant diacritics after class_0.
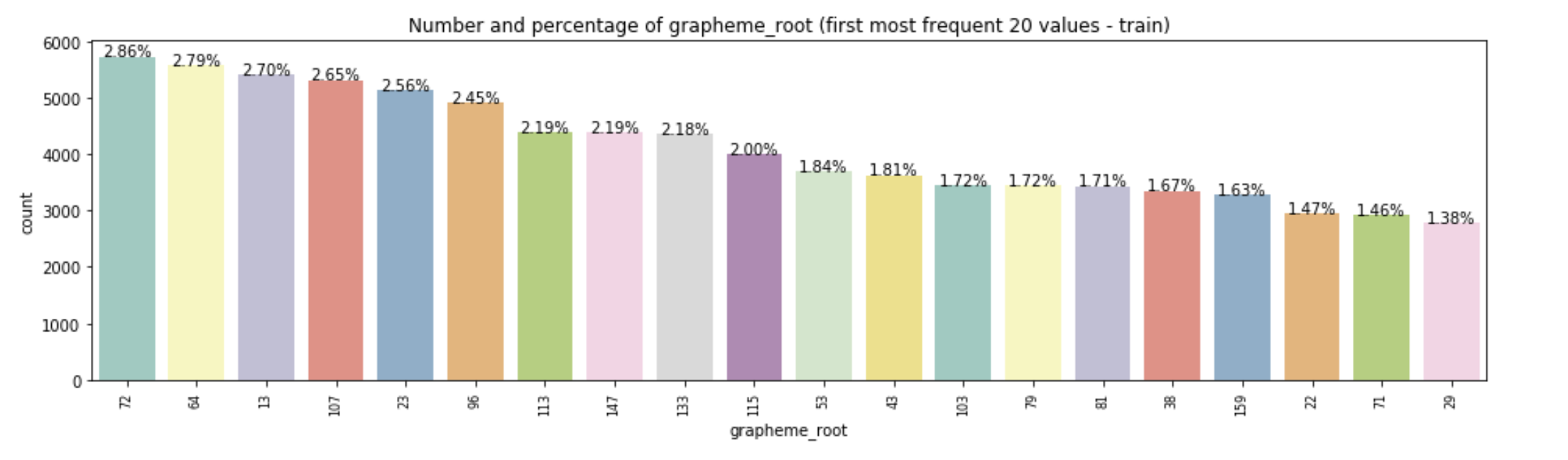
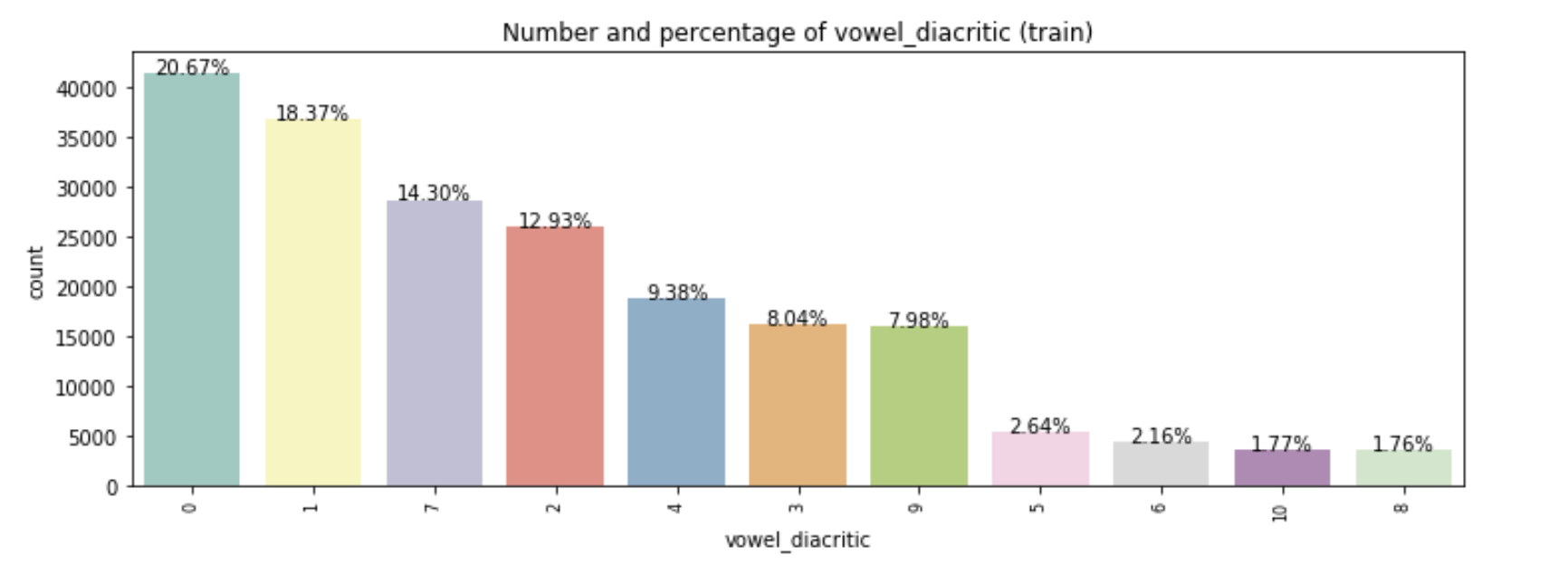
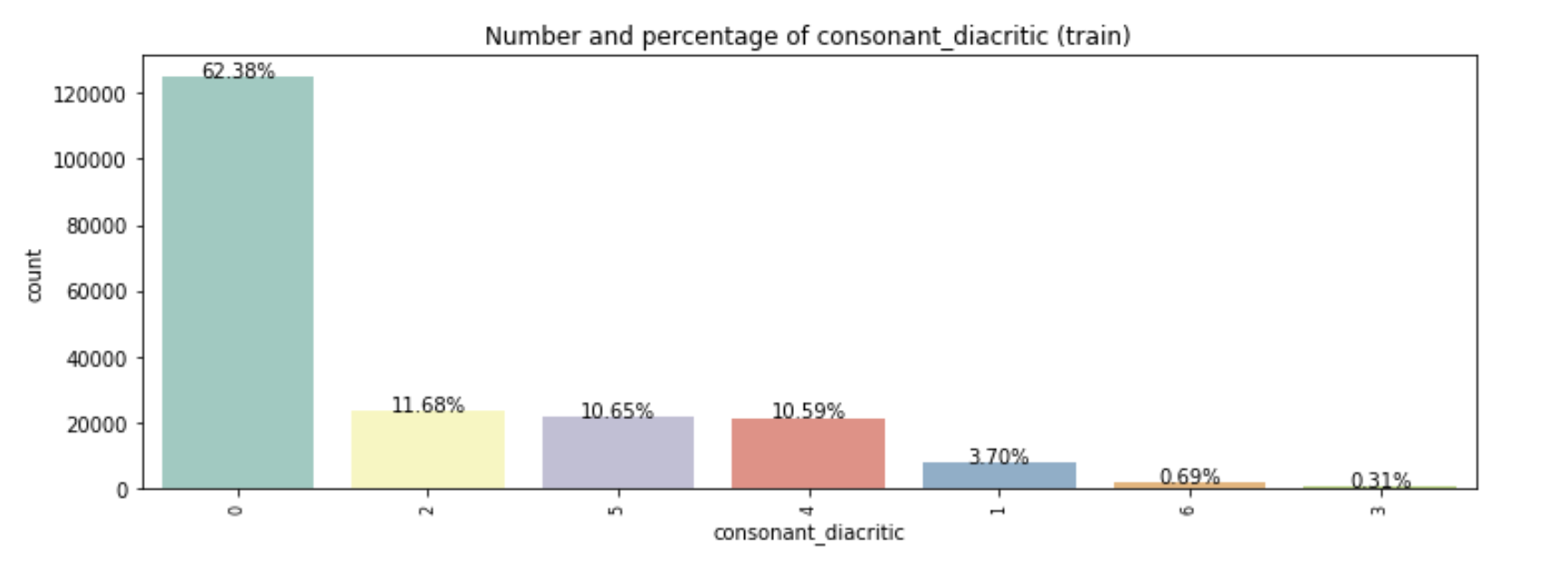
Building Baseline model:
The baseline model gives the initial accuracy scores and weights for further training process. We adapted Kaushal Shah’s Kaggle notebook for building the baseline model. We loaded and saved the data into the working space, and resized the images by center cropping the region of interest. The model includes 2D convolution layers, batch normalization, max pooling and dropouts to eliminate the risks of vanishing/exploding gradients problems and overfitting.
These 200,840 training handwritten grapheme images are stored separately in four parquets. For baseline model, due to the inefficiency of the model as well as the large size of training sets, we only trained the first parquet. The baseline accuracy scores are 88.5% for grapheme root, 94.3% for vowel and 96.0% for consonant.
Tensorboard:
Tensorboard visualizes how the model performed and checks underfitting/overfitting condition. For each component of the character, we got a tensorboard that traces the accuracy and the loss. The figure below is the tensorboard visualization of consonants training process.
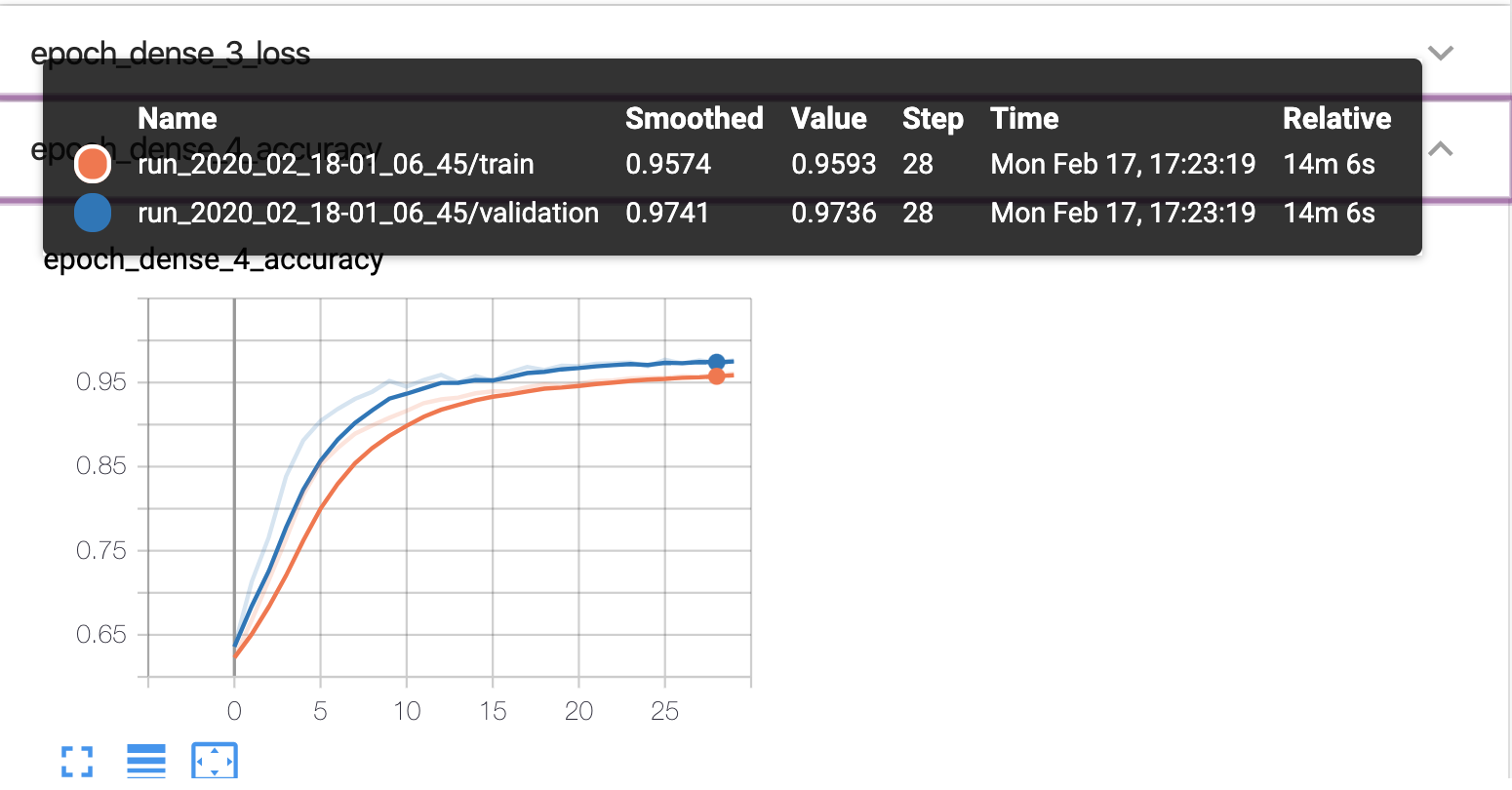
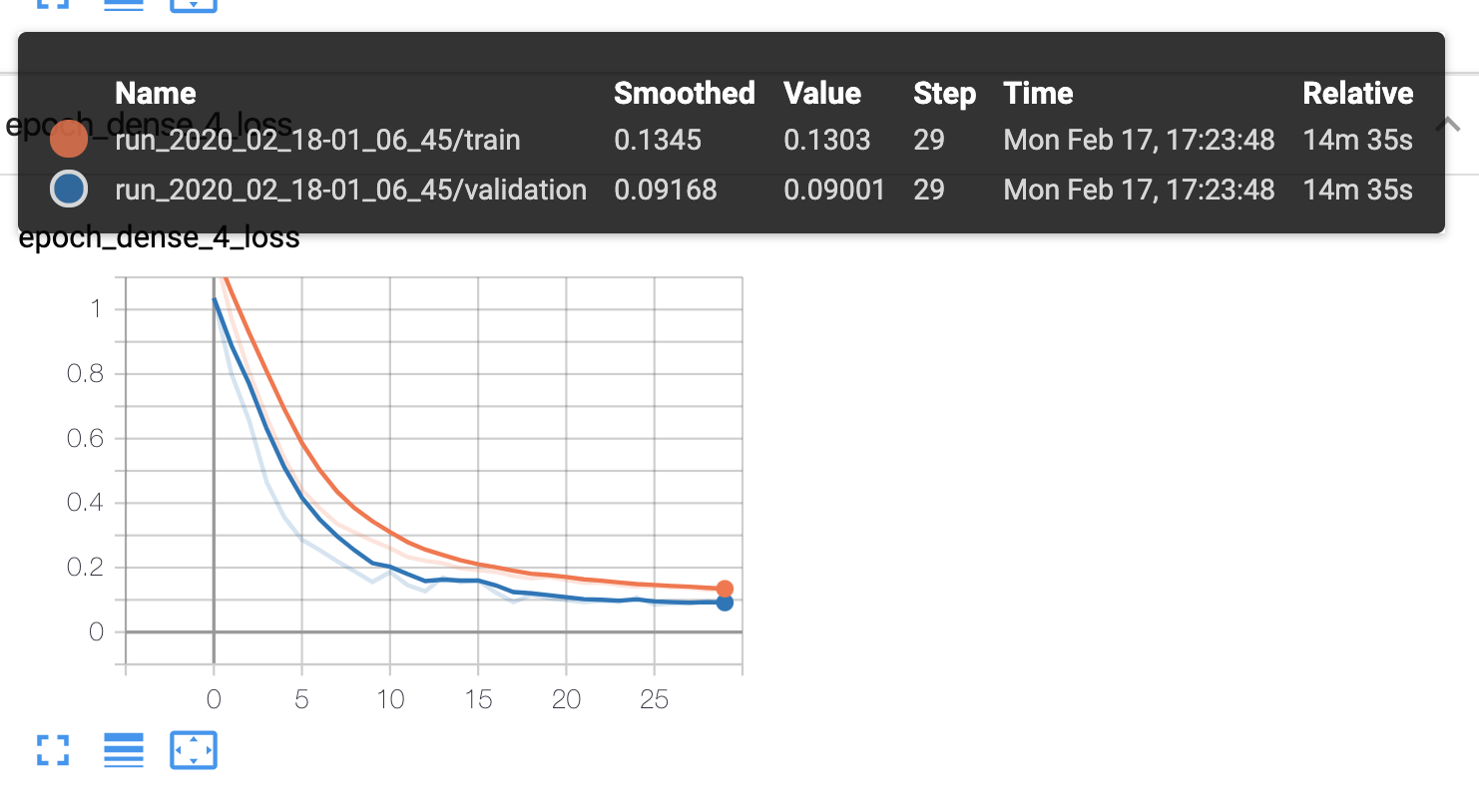
As we can see, the accuracy here represents consonant training is 96%, and is 97.5% for the validation. There is no overfitting or underfitting during the training process.
Next Step:
From this point, we will:
- Perform confusion matrix to evaluate predictions
- Tune hyperparameters to improve the model accuracy
- Implement data augmentation to diversify the input data and improve the model accuracy
- Modify DL model layers to improve accuracy
Links/documentation for the team’s baseline Kaggle entry:
Shout out for Sayan Samanta providing this beautiful Bengali handwritten image for us!