Background & Motivation
Bengali (bāṅlā / বাংলা or bāṅālī / বাঙালী) is the official language of Bangladesh and the second most spoken language in India. Considering the number of its users, there are significant benefits in developing models that can optically recognize images of the handwritten graphemes. Bengali has 49 letters (to be more specific 11 vowels and 38 consonants) in its alphabet, there are also 18 potential diacritics, or accents. This means that there are many more graphemes that added complexity results in ~13,000 different grapheme variations (compared to English’s 250 graphemic units).
This Kaggle project hopes to improve on approaches to Bengali recognition and to classify the components of handwritten Bengali. We obtained the dataset from Kaggle Research Code Competition (need competatition link) and we are given the images of a Bengali handwritten grapheme. We separately classified three elements in the image: grapheme root, vowel diacritics, and consonant diacritics. This blog post serves as a documentation of our learning experience. All secourses we used are listed in the reference list.
Overview
For the initial blog post, we preprocessed the given Bengali.AI Handwritten images, performed EDA and built a baseline model using a Convolutional Neural Network to classify the three parts (root, vowel and consonant) of each grapheme. Also, image augmentation was applied to boost performance. For the final blog post, we further improved the baseline model to optimize accuracy scores and speed up the learning process through model reorganization, hyperparameters tuning, and transfer learning. The final accuracy scores we achieved are 96.53% for root, 97.45% for vowel and 98.42% for consonant.
Final Model description
In the final model, we provided resized image data into convolution layers, and applied ELU activation to the matrix. We added as many convolutional layers until the result was satisfied. We performed batch normalization to reduce the dependence of gradients on the scale of the initial values, and dropouts to reduce interdependent learning among the neurons in the network. We also used max pooling to reduce dimensionality size. We flatten the output and fed it into a fully connected layer to classify each image into three parts.
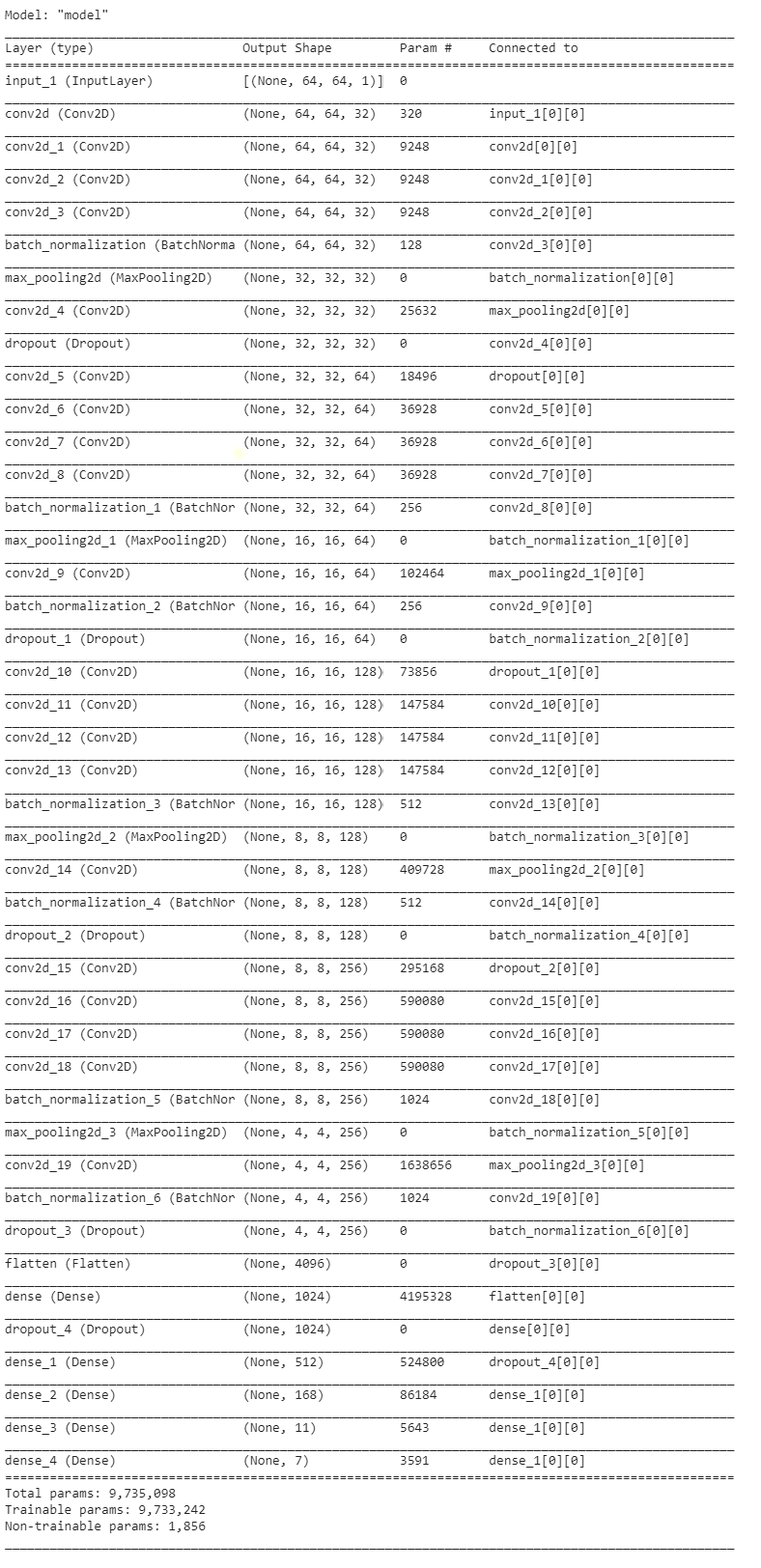
Parameter Selection & Other Enhancement:
Activation Function:
The baseline model used ReLU as the activation function, and we switched it to ELU in the final model. ReLU did not perform so well in our model since it suffers from a problem known as dying ReLU, meaning neurons will stop outputting anything but 0. Instead, we adopted ELU that outforms ReLU by alleviating vanishing gradients problem.
Learning Rate Scheduler:
Also, we changed the learning rate from constant value to learning rate scheduler which decreases the learning rate during the training process. We performed time-based decay, step decay and exponential decay, and the result turned out that exponential decay gave the best score.
Runtime Boosting:
Furthermore, we applied a boosting algorithm into the training process. It turns a weak model to a stronger one by fixing its weaknesses. The algorithm works by initially training a model on a small dataset and then taking all of the training data to test the model. When we trained the first model, we addressed its deficiencies, which allows us to train the subsequent model from baseline instead from scratch. During the baseline model training process, we saved the model weights for the final training. For the subsequent model training, we tried to freeze the convolutional layers, and the training time was even shorter but the accuracy is lower than the score from unfreezing the layers.
Final Results
| Accuracy score | Baseline Model | Improved Model |
|---|---|---|
| Grapheme Root | 0.8852 | 0.9653 |
| Vowel | 0.9444 | 0.9745 |
| Consonant | 0.9602 | 0.9842 |
Kaggle Entry:

Short-comings
- The shortcoming of ELU activation function is that it is slower to compute than the ReLU function, thus it is inefficient to train large dataset on the model.
- Another shortcoming is that the dataset does not have sufficient training points for the last few classes, and classification might not be as accurate as top classes of grapheme roots.
- For boosting, we train the final model in a way that overall models address deficiencies of the first model and speed up the process. However, the final model result includes randomness, meaning it might not give the satisfying score for every training.
Potential Improvements
- We could perform the confusion matrix to evaluate predictions.
- It is also feasible to modify Deep Learning model layers to improve accuracy.
- We can also try to train different model structures, such as Fully convolutional networks(FCN) or EfficientNet.
References
Article on data augmentation
Shout out for Sayan Samanta providing this beautiful Bengali handwritten image for us!